( 0702 회의록 )
0704 회의록
대회 초반부터 NLP로 해결해야 할 것 같은 느낌이 강력(!)하게 들어서 자연어처리를 이용한 추천시스템에 대해 간단하게 찾아보던 도중 네이버의 AI 추천시스템 AiRs 추천시스템에 관한 설명회 영상을 참고해서 방법론에 대해 공부했다.
이 영상에서 소개하는 추천 시스템 방법론은 크게 3가지로 볼 수 있다. 이 영상의 개발자님은 보통 개발자는 추천 시스템으로 협업 필터링 방법 중 FM 방법으로 가장 접근을 많이 하기 때문에 일부러 3가지 방법론 모두 소개한다고 말씀하신다.
< Naver AiRs 개발자가 말하는 추천시스템 접근 방법 3가지>
- Statistics-based
- 협업 필터링
- 딥러닝
1. Statistics-based 통계 기반 방법론 : Chi-square, Cross-Entrophy
- 카이스퀘어 방식 : 관측치와 예측치 차의 값을 가장 작게 만들어 추천 아이템을 예측한다.
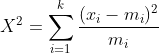
유저가 소비한 아이템의 예측치와 실제 소비한 관측치 차이를 이용한다. 예상보다 많이 본 상품 및 음악을 찾는 데 효과적이며, 상대적인 변화량을 찾고자 할 때 유용하다.
- Cross-entrophy 활용 : 정보의 손실량을 최소화하자. 보통 딥러닝의 손실함수로 유명하다.

* KL-Divergence : 이 값이 클수록 의외성이 있어 좋다. 즉, 이미 고객이 구매했을 법한 (들어봤을 법한) 상품이 아닌 "새롭지만 고객이 좋아할만한" 상품을 추천한다.

"P라는 분포가 Q라는 분포를 얼마나 잘 설명하는가?" 를 알고 싶을 때 Cross-entrophy를 활용한다. P와 Q의 분포가 다를 수록 유의미한 모델이라 볼 수 있다.
그러나 통계적 방법론은 세 가지 방법론 중 가장 정확도가 낮으므로 참고만 하고 넘어가자.
2. 협업 필터링
- User-based 사용자 기반 필터링 : 나랑 비슷한 사용자가 듣는 음악은 무엇일까?
- Item-based 아이템 기반 필터링
# 유사도 지표
- Cosine Similarity 코사인유사도
- Jaccard Index 자카드 인덱스
보통 유사도의 기본적인 아이디어는 A,B 상품이 서로 얼마나 유사한가?를 찾는 일이다.
그러나, 우리의 포인트는 '어떤 상품/음악이 유사하게 사용/듣게 될 가능성이 높은가?' 라는 것을 잊지 말자.
이러한 관점에서는 PMI라고 하는 정규화된 지표를 통해 두 사건 A,B 함께 발생한, 그러니까 음악 추천시스템에서는 사용자가 A,B곡을 같이 들었을 가능성을 보여주는 유사도 지표를 활용한다,
PMI (Point Mutual index) : 함께 발생한 빈도와 각 이벤트 발생 확률 모두 고려

# 협업 필터링과 MF(Matrix Factorization) : Latent Factor(잠재 요인, 은닉 벡터) 찾기
- MF에 대해 한계점
- 계산 많고, 학습속도가 느리다
- missing data를 negative 샘플로 사용 -> sparcity 문제 하에서는 올바른 결과 도출 불가
- 해결책? : Weighted ALS
- ALS를 이용해 한 쪽에 파라미터를 고정해서 찾는 방법 : 계산속도와 sparcity 문제를 개선할 수 있겠다.
- Weighted scheme : 미관측 데이터는 어떻게 쓸까?
행렬분해 방법론을 위해서는 최적화함수(ALS, SDG)에 대해서도 공부를 할 필요가 있겠다. 우선 지금까지 찾아본 추천 시스템에서는 ALS가 특히 결과가 괜찮다는 의견이 다수 있었다.
=> 그러나 우리의 경우 비선형식이기에 ALS는 효과가 없을 수도.
우리 팀의 경우, 머신러닝과 통계에 강점인 멤버가 있으므로 우선은 MF를 적극 활용하는 방법으로 우선 진행하는 편이 나을 것이라고 생각했다. (내 뇌피셜) 게다가 딥러닝 보다는 훨씬
3. 딥러닝 방법론 : RNN, CNN 활용
" 좋아할 만한" ?
- 나의 context 벡터와 가까운 아이템을 찾아 추천한다.
- 인공 신경망을 통한 유저-아이템 도출
# 장점이자 단점
굉장히 많은 수의 데이터를 필요로 한다.
작동 구조
Document Sequence -> Doc2Vec -> LSTM Layer -> RecVec
Document Sequence : 유저가 본 문서 시퀀스
Doc2Vec : 유저-문서 간 벡터 연산
LSTM Layer : 유저로그가 없는 신규뉴스에 RNN 통해 학습된 유저임베딩 정보를 활용?
RecVec : 유저가 볼 문서를 예측.
또한, 데이터 기간이나 범위에 대해서도
- Session- based : 최신 데이터만 넣기
- Historical-based : 모든 데이터 넣기